Publicado
- 4 min tiempo de lectura
Riesgos del RAG en industria: cuando una respuesta correcta no es necesariamente fiable

El Retrieval-Augmented Generation (RAG) se ha convertido en una de las arquitecturas más prometedoras para aplicar modelos de lenguaje a documentación técnica. En teoría, permite responder preguntas basándose exclusivamente en información recuperada de manuales, planos o especificaciones.
En entornos industriales, esto parece ideal. Sin embargo, existe un problema estructural que rara vez se menciona: utilidad no es lo mismo que verificabilidad.
Un sistema puede responder correctamente el 80% de las veces. Pero en industria, el 5% incorrecto puede ser inaceptable.
Cómo funciona un RAG estándar
Un RAG típico sigue un flujo lógico donde la respuesta final depende de la consulta del usuario y de los documentos recuperados :
Desde fuera, el proceso parece razonable: el sistema busca fragmentos (chunks) relevantes en una base vectorial y el modelo de lenguaje los sintetiza. Pero aquí empiezan los matices.
💡 Explicación para principiantes: ¿Qué es el RAG?
Imagina que tienes un examen de historia pero no has estudiado. Sin embargo, el profesor te deja tener el libro abierto. Cuando te hacen una pregunta, tú buscas rápidamente la página adecuada (esto es el Retrieval) y luego escribes la respuesta con tus propias palabras basándote en lo que has leído (esto es la Generation). El problema en la industria es: ¿qué pasa si el libro tiene una errata o tú interpretas mal un esquema técnico?
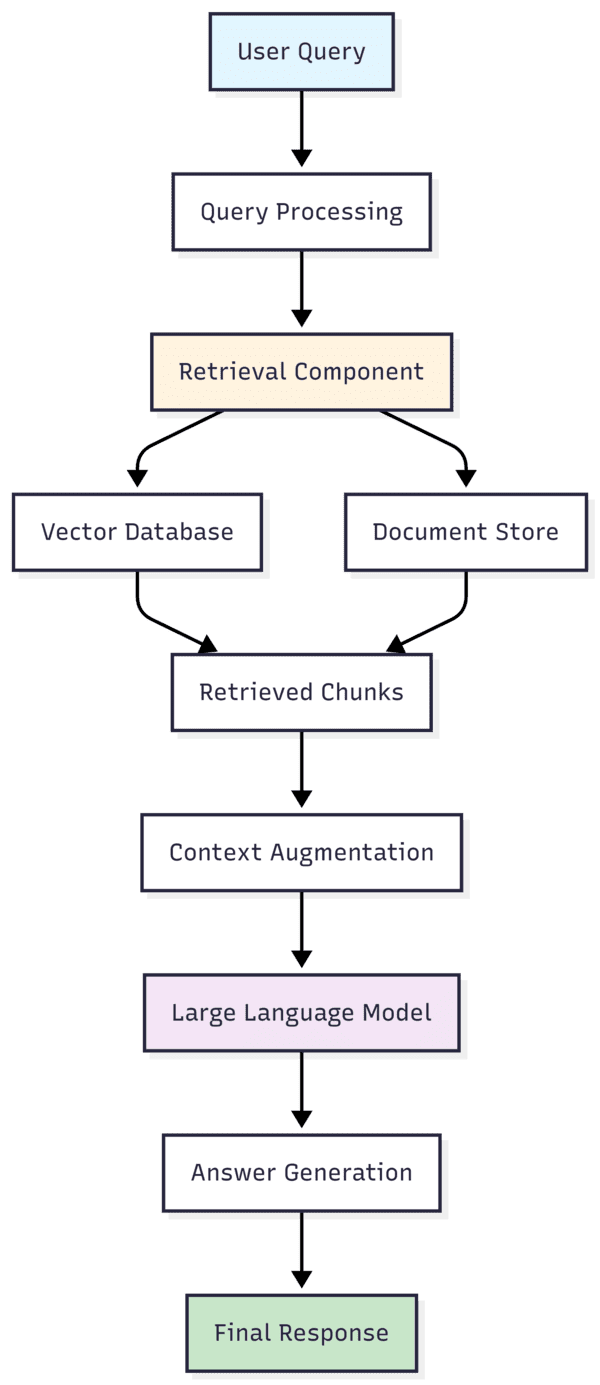
Figura 1. Flujo típico de un sistema RAG estándar: recuperación semántica de fragmentos documentales y síntesis posterior por parte del modelo de lenguaje, sin validación estructural explícita.
El problema oculto: La “ilusión” de corrección
Cuando aplicamos esta arquitectura a manuales técnicos o procedimientos eléctricos, el flujo no es neutro. El sistema puede generar una respuesta coherente aunque la base documental no sea sólida o la recuperación sea incompleta.
Cinco riesgos estructurales en documentación técnica
- Mezcla de fuentes sin jerarquía: Un RAG estándar no distingue entre un manual narrativo y un plano eléctrico. En industria, un esquema oficial tiene más autoridad que un documento auxiliar, pero para el embedding, ambos son solo “texto recuperado”.
- Inferencia silenciosa: Si faltan pasos en un procedimiento, el modelo puede completarlos implícitamente para que la respuesta sea “coherente”. En un contexto creativo es una ventaja; en un procedimiento de alta tensión, es un riesgo crítico.
- Confusión entre similitud y evidencia: Un sistema puede encontrar un texto “similar” semánticamente, pero eso no garantiza que contenga el valor nominal exacto o la unidad de medida explícita requerida.
- Falta de diferenciación de consultas: No es lo mismo localizar un elemento que verificar un valor de seguridad. Tratar todas las consultas como equivalentes diluye la precisión.
- Optimización para responder vs. Bloqueo: La mayoría de sistemas están diseñados para dar una respuesta siempre. En entornos técnicos, la respuesta correcta suele ser: “No existe evidencia documental suficiente”.
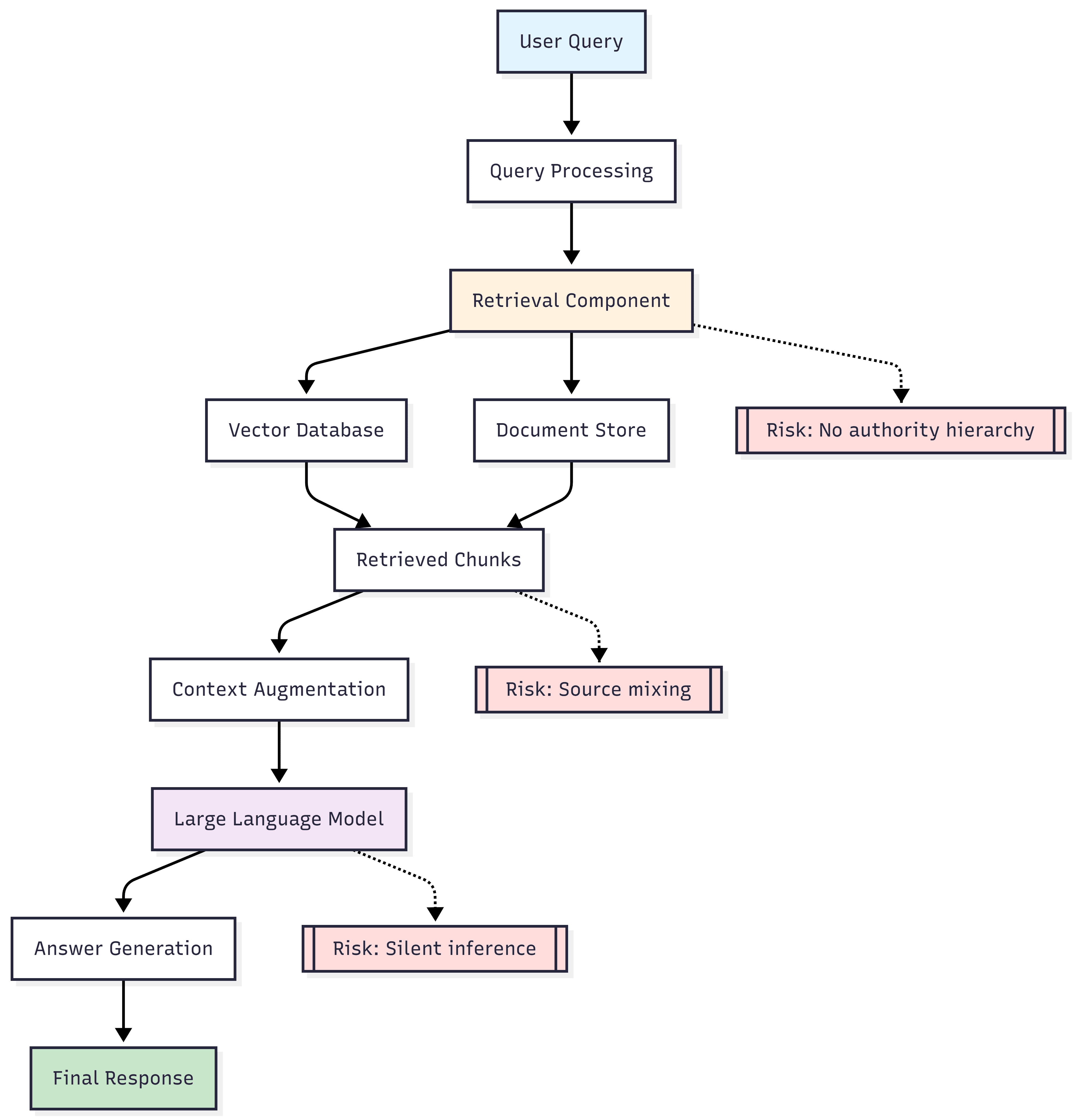
Figura 2. Puntos críticos en un RAG convencional: ausencia de jerarquía documental, mezcla de fuentes heterogéneas e inferencia implícita durante la generación de la respuesta.
Utilidad vs. Verificabilidad
Muchos sistemas RAG actuales se sitúan en un cuadrante peligroso: alta utilidad pero baja verificabilidad.
| Característica | RAG Estándar (Alta Utilidad) | RAG Industrial (Alta Verificabilidad) |
|---|---|---|
| Objetivo | Responder siempre de forma natural. | Proporcionar evidencia rastreable. |
| Manejo de duda | Tiende a alucinar sutilmente. | Bloqueo epistemológico (no sabe/no contesta). |
| Fuentes | Mezcla de fragmentos aleatorios. | Jerarquía de autoridad explícita. |
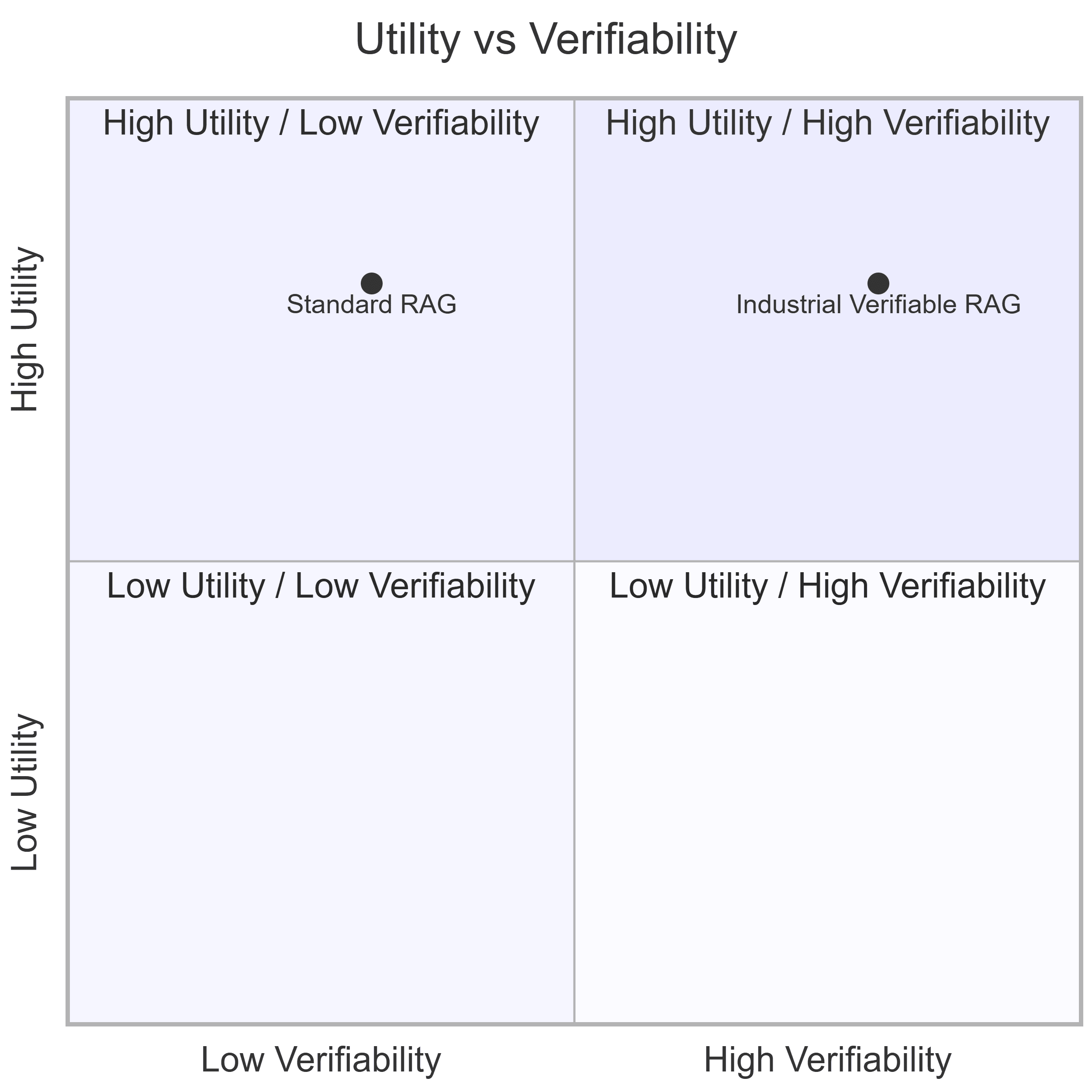
Figura 3. Relación entre utilidad y verificabilidad en sistemas RAG: una alta capacidad de respuesta no garantiza evidencia documental estructurada ni trazabilidad técnica suficiente.
Para medir la fiabilidad, se evalúa la fidelidad documental () como la relación entre las afirmaciones de la respuesta () que tienen sustento directo en la fuente ():
Qué debería exigir una arquitectura RAG en producción
Si queremos llevar la IA a la planta real, necesitamos sistemas que no solo sean útiles, sino deterministas. Deberíamos exigir:
- Jerarquía explícita de autoridad documental.
- Capacidad de bloqueo cuando no hay datos suficientes.
- Validación posterior a la generación mediante agentes de crítica.
- Separación clara entre localizar un dato, verificar un valor y explicar un proceso.
En el siguiente artículo exploraremos qué significa realmente diseñar un RAG determinista y cómo construir sistemas donde el error sea gestionado por diseño, no por azar.
Si estás pensando en aplicar estas tecnologías a tu base de conocimiento técnica, puedes consultar nuestra guía sobre arquitectura RAG industrial para evitar los errores comunes de implementación.
Raúl Jáuregui Consultor IA e I+D+i en ViaLabs Digital
¿Te interesa saber cómo estamos resolviendo el bloqueo epistemológico en proyectos reales? Sigamos la conversación.

: El error conceptual del RAG estándar en entornos técnicos")
")

Machine Learning aplicado a negocio
Soy Raúl Jáuregui, consultor de I+D+i y también trabajo en proyectos de ML orientados a producción real, no solo prototipos. Si quieres pasar de experimento a sistema robusto, hablemos.
Ver servicio