Publicado
- 19 min tiempo de lectura
Agentes IA para empresas: de asistentes reactivos a vigilancia proactiva

Durante los últimos meses he ido cambiando mi forma de pensar sobre la inteligencia artificial aplicada al trabajo diario. Al principio, como casi todo el mundo, usaba la IA como un asistente al que le hacía preguntas: escribir un texto, resumir una idea, revisar código, preparar un email o ayudarme a entender un problema técnico. Eso ya tiene mucho valor, pero también tiene una limitación evidente: el asistente espera a que yo me acuerde de preguntarle.
Y en una empresa pequeña, en una consultoría o en cualquier actividad profesional con muchos frentes abiertos, ese es precisamente uno de los grandes problemas. No siempre fallamos porque no sepamos qué hacer. Muchas veces fallamos porque se nos quedan cosas abiertas: un presupuesto sin seguimiento, una oportunidad en el CRM que nadie revisa, una web que empieza a dar errores, una dependencia técnica que se queda desactualizada, un contacto interesante al que no escribimos después de una reunión o un artículo del blog que nunca reutilizamos en LinkedIn.
Por eso estoy diseñando Secretario IA / OpenClaw con una idea diferente. No quiero simplemente tener un chatbot más. Quiero construir una pequeña infraestructura de agentes IA para empresas, empezando por mi propio caso, que sea capaz de vigilar fuentes de información, detectar cambios relevantes y avisarme cuando de verdad hay algo que merece mi atención.
La frase que resume esta idea es sencilla:
La IA útil no es la que contesta mejor, sino la que sabe qué debe vigilar y cuándo debe interrumpirte.

El problema de los asistentes IA reactivos
Los asistentes IA actuales son muy potentes, pero en la mayoría de los casos siguen funcionando de forma reactiva. Tú abres una conversación, escribes una pregunta y recibes una respuesta. Eso sirve para muchas tareas, pero no resuelve por sí solo la continuidad operativa de una empresa.
En mi caso, puedo preguntarle a una IA cómo revisar un error en Docker, cómo escribir un email de seguimiento o cómo preparar un artículo para el blog. Pero si soy yo quien tiene que acordarse de revisar el servidor, mirar el CRM, buscar vulnerabilidades, actualizar contactos y reutilizar contenidos, el sistema sigue dependiendo demasiado de mi memoria y de mi energía del día.
El modelo habitual es este:
Es útil, pero tiene un problema: todo empieza cuando el usuario pregunta. Si el usuario no pregunta, no ocurre nada.
El modelo que estoy buscando con Secretario IA es distinto:
La diferencia es importante. En el primer caso, la IA es una herramienta a la que recurro. En el segundo, la IA forma parte de una arquitectura operativa que me ayuda a mantener el control sobre áreas concretas de mi negocio.
Qué entiendo por agentes IA proactivos
Cuando hablo de agentes IA proactivos no me refiero a una IA que actúa sin control o que toma decisiones delicadas por su cuenta. Me refiero a agentes con responsabilidades claras, fuentes concretas y capacidad para generar avisos útiles.
Un agente proactivo debe ser capaz de vigilar una fuente de información, detectar cambios, comparar el estado actual con el anterior, resumir lo importante, priorizar el riesgo o la oportunidad, proponer una siguiente acción y avisar por el canal adecuado.
La clave está en que no todo aviso sirve. Una notificación que solo genera ruido no aporta valor. Una interrupción útil, en cambio, debe llegar con contexto, explicar por qué importa y proponer qué hacer después.
No quiero que OpenCTO me diga simplemente: “hay una vulnerabilidad”. Quiero que me diga algo parecido a esto:
He detectado una vulnerabilidad relevante en una dependencia usada por el proyecto X. Actualmente tienes instalada la versión A, la versión recomendada es B, afecta a este servicio y mi recomendación es actualizarla antes de desplegar nuevos cambios.
Ese es el salto entre una alerta técnica y un agente que ayuda de verdad.
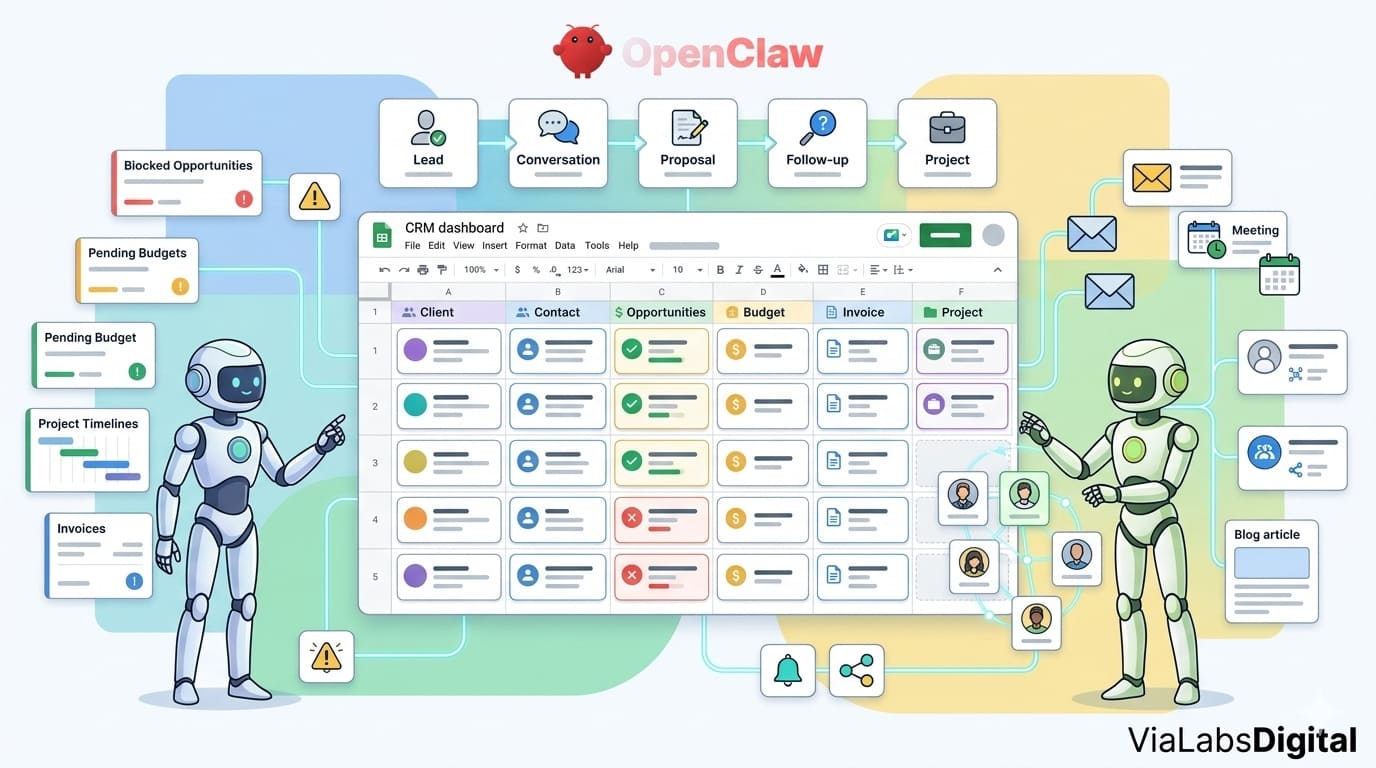
Arquitectura objetivo de OpenClaw
La arquitectura que estoy planteando separa dos piezas que conviene no mezclar: la obtención de información y la interpretación de esa información.
Por un lado están los scripts Linux, que se ejecutan mediante cron y se encargan de leer fuentes de datos. Pueden consultar logs, revisar Docker, mirar un package.json, leer un informe de monitorización, extraer información del CRM o detectar cambios en una carpeta del servidor. Pero estos scripts no toman decisiones. Su trabajo es recopilar información y generar un resumen estructurado.
Por otro lado están los crons de OpenClaw, donde entran los agentes lógicos. Estos agentes leen los resúmenes generados por los scripts, interpretan la información, priorizan, guardan trazabilidad y comunican por Slack lo que merece atención.
La regla de diseño es esta:
| Pieza | Responsabilidad | Qué no debe hacer |
|---|---|---|
| Scripts Linux | Obtener información, detectar cambios y generar resúmenes estructurados | Tomar decisiones de negocio o interrumpirme directamente |
| Agentes OpenClaw | Interpretar, priorizar, decidir si algo merece aviso y comunicarlo | Leer fuentes caóticas sin preparación previa |
| Slack | Recibir avisos útiles y permitir conversación con los agentes | Convertirse en un canal lleno de ruido |
| Obsidian | Guardar trazabilidad, memoria operativa y contexto | Sustituir al CRM estructurado |
| Google Sheets | Actuar como CRM operativo dentro de Google Workspace | Guardar memoria narrativa o decisiones largas |
El flujo completo sería:
Esto todavía está en construcción, pero el planteamiento es importante porque evita convertir la IA en una caja negra. Cada parte tiene una responsabilidad concreta.
La arquitectura técnica sobre la que estoy construyendo OpenClaw
Aunque en este artículo hablo de agentes IA de forma conceptual, en mi caso no es solo una idea teórica. Estoy construyendo esta arquitectura sobre OpenClaw, desplegado en Docker y adaptado a mis necesidades.
OpenClaw me sirve como motor de ejecución de agentes. No lo uso como una instalación cerrada, sino como una base que puedo modificar, actualizar y adaptar. Para ello parto de la imagen original en Docker y voy incorporando mis propias modificaciones, especialmente en la forma en que los agentes se conectan con mis fuentes de información y guardan memoria operativa.
La arquitectura tiene varias piezas:
| Pieza | Función |
|---|---|
| OpenClaw | Motor de ejecución de los agentes |
| Docker | Entorno donde despliego y actualizo el sistema |
| OAuth de ChatGPT | Autenticación y conexión con ChatGPT |
| Ollama | Modelo local de fallback |
| Slack | Canal principal de comunicación con los agentes |
| Obsidian | Memoria operativa y trazabilidad |
| Google Sheets | CRM estructurado dentro de Google Workspace |
| Scripts Linux | Lectura de fuentes, monitorización y generación de resúmenes |
| Crons | Ejecución periódica de revisiones y avisos |
Una parte importante es que no quiero depender de una única pieza. ChatGPT es el modelo principal, pero Ollama queda como modelo local de fallback. Esto me interesa porque, aunque el sistema use modelos potentes en la nube, quiero mantener una vía local para determinadas tareas o escenarios en los que convenga tener más control.
Obsidian no es el CRM: es la memoria de los agentes
Una distinción importante es que Obsidian no sustituye al CRM.
El CRM real está en Google Workspace, en una Google Sheet. Ahí deben vivir los datos estructurados: clientes, contactos, oportunidades, presupuestos, proyectos, facturas y estados.
Obsidian cumple otra función. Es la memoria operativa de los agentes. Es el lugar donde OpenCTO, OpenCIO y OpenCMO pueden guardar contexto, decisiones, incidencias, seguimientos y trazabilidad.
Por ejemplo, OpenCTO puede guardar una incidencia técnica detectada en el servidor; OpenCIO puede registrar que una oportunidad lleva demasiado tiempo parada; OpenCMO puede anotar que una persona apareció en una reunión y conviene añadirla al CRM; y cualquier agente puede dejar constancia de una recomendación, una decisión o una acción pendiente.
Esta separación me parece importante porque evita mezclar datos estructurados con memoria narrativa.
Google Sheets es la fuente de datos del CRM. Obsidian es la memoria viva de lo que ocurre alrededor de esos datos.
Tres agentes lógicos: OpenCTO, OpenCIO y OpenCMO
La idea no es tener un único asistente genérico para todo. Prefiero trabajar con tres agentes lógicos, cada uno centrado en un área crítica de mi actividad.
| Agente | Área | Función principal |
|---|---|---|
| OpenCTO | Tecnología e infraestructura | Vigilar servidor, webs, stack técnico, Docker, vulnerabilidades y flujo de OpenClaw |
| OpenCIO | Operación interna | Revisar Google Sheets, oportunidades, presupuestos, proyectos, facturas y seguimiento operativo |
| OpenCMO | Marketing, contactos y relaciones | Detectar acciones comerciales, contactos, leads, reuniones, LinkedIn, X/Twitter y contenidos |
Esta separación ayuda mucho porque cada agente puede tener sus propias fuentes, criterios de prioridad y tipo de aviso. No es lo mismo detectar una vulnerabilidad crítica en una web que recordar un presupuesto sin seguimiento o proponer una publicación para LinkedIn a partir de un artículo del blog.
OpenCTO: vigilancia técnica del servidor, webs y stack
OpenCTO es el agente que quiero dedicar a la parte técnica. Su objetivo es reducir riesgo y ayudarme a mantener controlada la infraestructura.
En mi caso, el servidor tiene Docker, Traefik, webs, servicios, contenedores, proyectos y distintas tecnologías. Además, cada nueva web o aplicación puede traer paquetes, dependencias, plugins o imágenes Docker que conviene registrar. Si no existe un inventario actualizado, es imposible hacer una vigilancia seria de vulnerabilidades.
Por eso OpenCTO debe encargarse de leer el cron de monitoring del servidor y webs, interpretar reportes del estado de los servicios, vigilar contenedores Docker, revisar cambios en /srv/webs, detectar nuevas aplicaciones, registrar paquetes y dependencias, mantener inventario de tecnologías, vigilar plugins WordPress, controlar imágenes Docker, buscar vulnerabilidades periódicamente, avisar de actualizaciones necesarias, detectar certificados próximos a expirar y preguntarme cuando aparezcan tecnologías desconocidas.
Una parte especialmente importante es el inventario vivo. Si implemento una nueva web o un nuevo proyecto, OpenCTO debe saber qué se ha instalado. No basta con que el proyecto funcione. Hay que contabilizar qué paquetes se añaden, qué versiones se usan, qué servicios quedan expuestos y qué componentes deben entrar en vigilancia de seguridad.
La lógica de inventario sería:
Y para vulnerabilidades:
La diferencia frente a revisar manualmente es clara. OpenCTO no debería sustituir mi criterio técnico, pero sí ayudarme a no olvidar lo importante.
OpenCIO: seguimiento del CRM y cierre de ciclos
OpenCIO es el agente orientado a la operación del negocio. En mi caso, el CRM está en Google Sheets y contiene información sobre clientes, oportunidades, presupuestos, proyectos, facturas y contactos. Esa información es muy valiosa, pero solo sirve si se revisa con continuidad.
El problema no es únicamente tener datos. El problema es que las oportunidades se enfrían, los presupuestos quedan sin seguimiento, los proyectos se bloquean y las facturas pendientes pueden perderse entre otras tareas.
OpenCIO debe revisar periódicamente el CRM y ayudarme a cerrar ciclos. Su función no es solo informativa, sino operativa.
Debe vigilar oportunidades abiertas, oportunidades sin actividad reciente, presupuestos enviados, presupuestos próximos a vencer, presupuestos sin seguimiento, proyectos bloqueados, proyectos sin siguiente acción, facturas pendientes, cobros vencidos y prioridades comerciales del día.
La lógica sería:
Y también:
La palabra clave aquí es empuje. OpenCIO debe tirar de mí suavemente para avanzar. No con ruido, sino con preguntas concretas: si quiero hacer seguimiento de un presupuesto, si una oportunidad tiene siguiente paso, si un proyecto sigue activo, si conviene enviar un recordatorio de factura o si hay que actualizar el estado en el CRM.
Para una pyme o un consultor, esto puede tener mucho valor. Muchas veces no hace falta una herramienta enorme de gestión. Hace falta que alguien revise lo que está abierto y te ayude a cerrar ciclos.
OpenCMO: relaciones, contactos, contenidos y visibilidad
OpenCMO es el agente orientado a marketing y desarrollo de relaciones. Su objetivo no es solo ayudarme a escribir posts, sino detectar oportunidades comerciales y relacionales que aparecen en el día a día.
En una actividad profesional como la mía, muchas oportunidades nacen de conversaciones, antiguos clientes, reuniones, contactos de LinkedIn, emails, recomendaciones o artículos que alguien lee. El problema es que esas señales aparecen dispersas y, si no se trabajan, se pierden.
OpenCMO debe observar leads que llegan desde formularios, contactos incompletos en el CRM, reuniones recientes, emails relevantes, personas con las que conviene reconectar, artículos publicados en el blog, contenidos reutilizables para LinkedIn, oportunidades de networking y posibles acciones para hacer crecer la red de contactos.
La lógica para leads sería:
Para relaciones:
Y para contenido:
Este punto me parece especialmente importante porque muchas veces se entiende el marketing como “publicar más”. Pero en una consultoría pequeña, el marketing también consiste en cuidar relaciones, hacer seguimiento, mantener vivo el CRM y convertir conocimiento en contenido.
OpenCMO debería ayudarme a responder preguntas como estas:
| Pregunta | Valor para el negocio |
|---|---|
| ¿A quién debería escribir esta semana? | Mantener relaciones vivas |
| ¿Qué contacto nuevo debería añadir al CRM? | Evitar que se pierda contexto comercial |
| ¿Con quién debería conectar en LinkedIn? | Aumentar red profesional |
| ¿Qué artículo del blog puedo convertir en post? | Reutilizar activos de contenido |
| ¿Qué conversación reciente puede dar lugar a contenido? | Convertir trabajo real en autoridad |
| ¿Qué lead merece seguimiento comercial? | No perder oportunidades |
El objetivo no es solo visibilidad. Es construir capital relacional.
Slack como canal operativo
Una decisión importante es usar Slack como canal principal de comunicación. No quiero tener que revisar diez paneles. Quiero que los agentes trabajen por debajo, pero que las interrupciones importantes lleguen a un lugar donde ya puedo conversar, responder y decidir.
Slack funciona como bandeja de entrada operativa, interfaz con los agentes, canal de avisos, espacio de conversación y punto donde puedo aprobar, descartar o pedir más contexto.
Esto hace que el sistema sea más natural. OpenClaw puede tener scripts, crons, memoria, CRM y fuentes externas, pero la experiencia para mí debe ser sencilla: recibir avisos útiles y poder responder desde un canal cotidiano.
Qué significa una interrupción útil
La proactividad solo tiene sentido si el sistema interrumpe bien. Si los agentes empiezan a enviar avisos irrelevantes, el sistema se convierte en otra fuente de ruido.
Por eso una interrupción útil debería tener una estructura mínima:
| Elemento | Pregunta que debe responder |
|---|---|
| Contexto | ¿Qué ha pasado? |
| Fuente | ¿De dónde sale esta información? |
| Importancia | ¿Por qué importa ahora? |
| Riesgo u oportunidad | ¿Qué puede pasar si no hago nada? |
| Acción recomendada | ¿Qué debería hacer? |
| Urgencia | ¿Es para hoy, esta semana o solo seguimiento? |
Un aviso útil no debería decir solo:
Hay presupuestos pendientes.
Debería decir algo más parecido a:
Hay dos presupuestos enviados hace más de diez días sin seguimiento. El más relevante es el de la empresa X porque está asociado a una oportunidad de mayor importe. Te propongo enviar hoy un email breve de seguimiento.
Ese tipo de comunicación es la que convierte un agente en una ayuda real.
Primera versión funcional
La primera versión no tiene que hacerlo todo. De hecho, es mejor empezar con una versión sencilla que genere informes y avisos periódicos.
El objetivo inicial sería tener un informe periódico de estado técnico, un informe periódico del CRM, un informe periódico de leads, contactos y contenidos, avisos cuando algo requiera atención, trazabilidad básica en Obsidian, comunicación en Slack y menos dependencia de menciones manuales.
Es decir, pasar de “yo invoco al agente cuando me acuerdo” a “el sistema revisa lo importante y me avisa cuando toca”.
| Primera versión | Resultado esperado |
|---|---|
| OpenCTO monitoring | Saber si servidor y webs están bien |
| OpenCTO inventario | Saber qué tecnologías y dependencias tengo |
| OpenCTO vulnerabilidades | Recibir avisos de riesgos técnicos relevantes |
| OpenCIO CRM diario | Ver prioridades comerciales y operativas |
| OpenCIO presupuestos/facturas | Evitar seguimiento perdido |
| OpenCMO leads/contactos | No perder oportunidades relacionales |
| OpenCMO contenido | Reutilizar artículos y aumentar visibilidad |
Qué puede aprender una pyme de este enfoque
Aunque este proyecto nace de mi propio uso, creo que la idea es aplicable a muchas pymes. No todas necesitan empezar con una gran plataforma de inteligencia artificial. Muchas podrían empezar con algo más concreto: elegir qué fuentes merece la pena vigilar y qué interrupciones serían realmente útiles.
Una empresa industrial podría vigilar incidencias, mantenimientos, documentación técnica o repuestos. Una asesoría podría vigilar vencimientos, expedientes y comunicaciones. Una consultora podría vigilar oportunidades, propuestas y clientes inactivos. Una empresa de servicios podría vigilar leads, presupuestos y reseñas. Una web comercial podría vigilar formularios, rendimiento, SEO y oportunidades de contenido.
La pregunta no es solo “qué puede responder la IA”, sino:
¿Qué debería estar mirando la IA por mí?
Esa pregunta cambia completamente el enfoque.
Beneficios que busco con Secretario IA
El beneficio principal no es automatizar por automatizar. Lo que busco es reducir fricción mental y operativa.
En la práctica, quiero conseguir menos carga mental, menos olvidos, mejor seguimiento comercial, más control técnico, más continuidad entre conversaciones, más trazabilidad, más capacidad de cerrar ciclos, más reutilización del contenido y una relación más natural con la IA dentro de mi forma real de trabajar.
Si OpenCTO reduce el riesgo técnico, OpenCIO evita que se pierdan oportunidades y OpenCMO me ayuda a hacer crecer relaciones y visibilidad, entonces Secretario IA deja de ser un experimento y empieza a parecerse a una pequeña capa de inteligencia operativa sobre mi negocio.
Una arquitectura todavía en construcción
Es importante decirlo con claridad: este sistema todavía no está terminado.
Algunas piezas ya existen, otras están en desarrollo y otras forman parte de la arquitectura objetivo. La conexión con Google Sheets, por ejemplo, todavía tengo que consolidarla, pero el diseño está claro: Google Sheets será el CRM estructurado, Obsidian será la memoria operativa y Slack será el canal donde los agentes me interrumpan con avisos útiles.
Me interesa contar este proceso porque muchas veces se habla de agentes IA como si fueran productos mágicos ya terminados. Mi experiencia es otra: el valor aparece cuando empiezas a conectar la IA con tus fuentes reales de trabajo, defines responsabilidades claras y decides qué merece ser vigilado.
No se trata de tener una IA que lo haga todo.
Se trata de construir un sistema que mire las cosas importantes antes de que se pierdan.
En evolución
Todavía no está terminado, pero el planteamiento de OpenClaw marca claramente hacia dónde quiero llevar Secretario IA.
No quiero tres chatbots.
Quiero tres sistemas de vigilancia inteligente sobre áreas críticas de mi actividad:
- tecnología,
- operación,
- y marketing.
La IA, bien integrada, no debería limitarse a esperar instrucciones. Debería ayudar a mirar donde hay que mirar, detectar lo que cambia y generar interrupciones útiles cuando merece la pena actuar.
Ese, para mí, es el verdadero salto de los agentes IA para empresas: no que hablen mejor, sino que ayuden a que el negocio no pierda el hilo.
¿Quieres aplicar este enfoque en tu empresa?
Si estás pensando en incorporar inteligencia artificial a tu empresa, quizá el primer paso no sea crear un chatbot. Quizá el primer paso sea identificar qué procesos, fuentes de información o áreas críticas deberían estar vigiladas.
En ViaLabs Digital ayudo a empresas a aterrizar la IA en casos de uso concretos: automatización, agentes IA, asistentes internos, CRM, documentación técnica, procesos comerciales y sistemas de apoyo a la toma de decisiones.
La pregunta inicial puede ser muy sencilla:
¿Qué debería vigilar una IA por tu empresa para que tú puedas decidir mejor?
Más sobre Consultoría en IA

RAG industrial vs buscador: por qué no estamos hablando de lo mismo

Checklist: ¿Está tu PyME lista para aplicar IA?

Machine Learning: ejemplos para empresas
Ver 5 artículos más

Arquitectura de IA verificable
Soy Raúl Jáuregui, consultor de I+D+i y también diseño sistemas de IA para entornos donde la trazabilidad y la autoridad documental son críticas. Si estás evaluando RAG industrial o automatización documental, podemos analizar tu caso.
Ver servicio